Here is the finished edited video:
The first version is in standard definition quality and the second is HD video.
Friday, 7 December 2012
Friday, 30 November 2012
Week 10: Lab (video and audio practice)
Today's lecture was about video processing, so during the lab our task was to take raw footage shot by a digital video camera man and edit it into a short film that lasted 1 minute. The footage was of bird life around a small Scottish loch.
The criteria of the task were:
- You should apply appropriate backing music (and occasionally tastefully mix this with original audio in the original footage). Music has been made available to you by a sound engineer and is downloadable.
- The final film should attempt to emote certain subjective qualities such as "drama and cuteness" as its main selling points.
- The film should be exactly 1 minute long.
- The film should include at least three sub-scenes editing together smoothly to create a natural flow to the final movie.
- You may use any of the features/effects/transitions of the video editing and audio editing software that you employ to make your final product attractive.

The criteria of the task were:
- You should apply appropriate backing music (and occasionally tastefully mix this with original audio in the original footage). Music has been made available to you by a sound engineer and is downloadable.
- The final film should attempt to emote certain subjective qualities such as "drama and cuteness" as its main selling points.
- The film should be exactly 1 minute long.
- The film should include at least three sub-scenes editing together smoothly to create a natural flow to the final movie.
- You may use any of the features/effects/transitions of the video editing and audio editing software that you employ to make your final product attractive.
Week 10: Lecture (moving image and video)
The Moving Image
John Logie Baird is often credited with inventing the television, but in fact despite designing and making a working mechanical TV system, his system was not adopted due to it being so unreliable.

Persistence of Vision
'Persistence of Vision' is an old theory that now is not believed to be true. It is the phenomenon of the human eye were an after image was thought to persist for approximately one twenty-fifth of a second on the retina. This is now regarded as the 'myth of persistence' and it is no longer accepted that human perception of motion (in the brain) is the result of persistence of vision (in the eyes). A more modern and more plausible theory to explain motion perception are two distinct perceptual illusions : phi phenomenon and beta movement.
The bitrate is the number of bits that are processed/conveyed per unit of time. It describes the rate at which bits are transferred from one location to another (i.e. it measures how much data is transmitted in a given amount of time).
Interlaced and Progressive video
Interlaced video is a technique of doubling the perceived frame rate without consuming extra bandwidth. The TV tricks your eyes by first drawing the odd number lines on the screen 25 times per second. Then the even lines of the next frame and so on. Progressive video does not interlace and appears sharper.
Display resolution
The display resolution of a digital television, computer monitor or display device is the number of distinct pixels in each dimension that can be displayed. Modern HD televisions can display 1080i or 1080p - the 'i' and 'p' stand for interlaced or progressive video.
John Logie Baird is often credited with inventing the television, but in fact despite designing and making a working mechanical TV system, his system was not adopted due to it being so unreliable.
Persistence of Vision
'Persistence of Vision' is an old theory that now is not believed to be true. It is the phenomenon of the human eye were an after image was thought to persist for approximately one twenty-fifth of a second on the retina. This is now regarded as the 'myth of persistence' and it is no longer accepted that human perception of motion (in the brain) is the result of persistence of vision (in the eyes). A more modern and more plausible theory to explain motion perception are two distinct perceptual illusions : phi phenomenon and beta movement.
Bitrate
The bitrate is the number of bits that are processed/conveyed per unit of time. It describes the rate at which bits are transferred from one location to another (i.e. it measures how much data is transmitted in a given amount of time).
Interlaced and Progressive video
Interlaced video is a technique of doubling the perceived frame rate without consuming extra bandwidth. The TV tricks your eyes by first drawing the odd number lines on the screen 25 times per second. Then the even lines of the next frame and so on. Progressive video does not interlace and appears sharper.
Display resolution
The display resolution of a digital television, computer monitor or display device is the number of distinct pixels in each dimension that can be displayed. Modern HD televisions can display 1080i or 1080p - the 'i' and 'p' stand for interlaced or progressive video.
Video file formats
I decided to research more about video file formats and how
they are used.
Platform: PC
File formats used:
WMV (Windows
Media Video): Microsoft’s family of proprietary video codecs, including WMV 7,
WMV 8 and WMV 9. This format uses the VC-1 codec.
MPEG-4: a
standard developed by the MPEG (Moving Picture Experts Group)
MPEG-2: an
older standard developed by the MPEG (Moving Picture Experts Group)
AVI (Audio
Video Interleave): a multimedia container format introduced by Microsoft in
1992.
FLV (Flash
Video): Flash video files usually contain material encoded with codecs
following the Sorenson Spark or VP6 video compression formats. It is developed
by Adobe and used on the popular video streaming site YouTube.
MOV (Apple
QuickTime Movie): common multimedia format often used for saving movies-
compatible with both Macintosh and Windows. QuickTime format uses the H.264 codec.
PC: WMV (Windows
Media Video)
Windows Media Video 9 (WMV9) is Microsoft’s implementation
of the VC-1 codec.
WMV9 supports three profiles: Simple, Main and Advanced. The
Simple and Main profiles support a wide range of bit-rates. These include
bit-rates appropriate for high-definition content as well as video on the
internet at dial-up connection speeds. The Advanced profile supports higher
bit-rates.
VC-1 can be used to compress lots of different streaming and
downloadable video content, from podcasts to HD movies on demand. It is
designed to achieve state-of-the-art compressed video quality at bit rates that
can vary from very low to very high. It can easily cope with 1920 x 1080 pixel
video at 6-30 Mbps for high-definition video. It is capable of handling up to a
maximum bit rate of 135 Mbps. VC-1 works using a block-based motion
compensation and spatial transform scheme similar to that used in other video
compression standards such as H.264 and MPEG-4.
Platform: Apple
Macintosh
File formats used:
MOV (Apple
QuickTime Movie): the standard format that QuickTime uses, along with MPEG-4.
MPEG-4: a
standard developed by the MPEG (Moving Picture Experts Group)
MPEG-2: an
older standard developed by the MPEG (Moving Picture Experts Group). Only
supported by the most recent version of Apple’s operating system, OS X Lion.
AVI (Audio
Video Interleave): a multimedia container format introduced by Microsoft in
1992.
Apple Macintosh: MOV
(QuickTime Movie)
The MOV video file format is a QuickTime movie. It is used
for saving movies and other video files and uses a proprietary compression
algorithm developed by Apple, which is compatible with both Macs and PCs. The
format is a multimedia container file that contains one or more ‘tracks’- which
each store a particular type of data including audio, video, effects or text
(e.g. for subtitles). Each of the tracks either contains a digitally-encoded
media stream or a data reference to the media stream located in another file.
Both the MOV and MP4 formats can use the same MPEG-4 codec
(also known as H.264), so they are mostly interchangeable in a QuickTime-only
environment. The codec uses lossy compression, which means
that an algorithm is used to remove any image data that is unlikely to be
noticed by the viewer. Lossy compression does not retain the original data
meaning that the data that is removed is lost. The amount of data lost depends
on the degree of the compression.
MP4/MPEG-4 - based on
MOV (QuickTime Movie)
MP4 is a video file format that uses MPEG-4 compression,
which is a standard developed by the Moving Picture Experts Group (MPEG). It
uses separate compression for both the audio and video tracks. The video is
compressed using AAC compression, which is the type of compression used in .aac
files.
MPEG-4 uses lossy compression, which uses an algorithm to
remove image information that is unlikely to be noticed by the viewer. Lossy
compression does not retain the original data meaning that the data that is removed
is lost. The amount of data lost depends on the degree of the compression.
The Apple iTunes store uses the M4V file extension for their
MP4 video files, including TV episodes, movies and music videos. These files
use MPEG-4 compression but also may be copy-protected using Apple’s FairPlay
digital rights management (DRM) copy protection. This means to play the file
the computer must be authorised to access the account it was purchased with.
Comparison of file
formats/codecs
MPEG-4/H.264 and VC-1 are both industry standards. However,
just because a platform or mobile device supports one of these “standards,” it
doesn’t guarantee compatibility, because H.264 and VC-1 consist of many
different “Profiles” and “Levels.”
A Profile outlines a specific set of features that are
required in order to support a certain delivery platform. A Level gives the
limits of the Profile, such as the maximum resolution or bit-rate. H.264
Profiles that are suitable for web video applications are: Baseline Profile
(BP) for limited computing power and Main Profile (MP) for typical user’s
computers. VC-1 uses different options- these are Low and Main Profiles, both
at low, medium or high levels depending on the user’s target platform.
At high bit-rates, the differences between MPEG-4/H.264 and
VC-1 are small:
- Under high bandwidth stress, H.264 tends to degrade to softness instead of blockiness, while VC-1 tends to retain more detail, but can show more artefacts due to its stronger in-loop deblocking filter. At web/download bit-rates, both codecs offer great quality and there is no difference between them.
- The MPEG-4/H.264 codec tends to take more CPU power to decode at maximum resolution. Comparing VC-1 Advanced Profile and H.264 High Profile, each with all of its options turned on, VC-1 can decode about twice as many pixels per MIPS (million instructions per second). This is more important when considering HD-resolution content than lower resolution content and doesn’t matter at all when there’s a hardware decoder. When constrained by software decoder performance, VC-1 can handle Advanced Profile, while H.264 is limited to Baseline, where VC-1 outperforms H.264 in quality/efficiency. This has become an important consideration in recent years, because consumer broadband access has outpaced the hardware upgrade cycle of many households and businesses.
- While there do not seem to be many differences between the VC-1 and MPEG-4/H.264 in terms of desktop computing (except for HD quality video), the Windows Media Video format has considerably less support on the Mac platform so H.264 has the advantage there. There is not the same difference in support on the Windows PC platform, however since the Windows Media Video format (and therefore VC-1 codec) is proprietary to that platform it would make sense to say it has a slight advantage.
Friday, 23 November 2012
Week 9: Lab (Adobe Premiere Pro)
During today's lecture we continued looking at image processing. Next week we start looking at video processing so the task for today's lab was to research Adobe Premiere Pro and watch several tutorials on how to use it.
This is the basic interface of Adobe Premiere Pro CS5.5:

Since I studied Interactive Media at college for two years I have used Adobe Premiere Pro before in my video classes. I used both Adobe Premiere Pro 2.0 (at college) and Premiere Pro CS4/CS5.5 (at home) so I am quite familiar with how to perform basic editing techniques on video clips, using simple effects and exporting into different file formats optimised for different platforms - including PC, Mac, iOS, Android and other mobile devices.
This is the basic interface of Adobe Premiere Pro CS5.5:

Since I studied Interactive Media at college for two years I have used Adobe Premiere Pro before in my video classes. I used both Adobe Premiere Pro 2.0 (at college) and Premiere Pro CS4/CS5.5 (at home) so I am quite familiar with how to perform basic editing techniques on video clips, using simple effects and exporting into different file formats optimised for different platforms - including PC, Mac, iOS, Android and other mobile devices.
Week 9: Lecture (digital image processing)
What is digital image processing?
The lecture divided DIP into four common categories: analysis, manipulation, enhancement and transformation.
Analysis
These operations provide information on the photo-metric features of an image, such as a histogram or colour count.
Manipulation
Operations such as flood fill and crop are classed as manipulating the image.
Enhancement
To try and enhance an image operations such as heightening the contrast, enhancing the edges or anti-aliasing are used.
Transformation
Images can be transformed using operations such as skew, rotate and scale.
Image processing
Images take up a lot more memory storage than audio files. Compression algorithms are used to reduce the file size without losing quality or data. This allows more image files to be stored in the same amount of space.

The lecture divided DIP into four common categories: analysis, manipulation, enhancement and transformation.
Analysis
These operations provide information on the photo-metric features of an image, such as a histogram or colour count.
Manipulation
Operations such as flood fill and crop are classed as manipulating the image.
Enhancement
To try and enhance an image operations such as heightening the contrast, enhancing the edges or anti-aliasing are used.
Transformation
Images can be transformed using operations such as skew, rotate and scale.
Image processing
Images take up a lot more memory storage than audio files. Compression algorithms are used to reduce the file size without losing quality or data. This allows more image files to be stored in the same amount of space.
The optical nerves work like wires that connect the eyes to the brain. Digital image processing allows technology in lenses to be implemented in the same way. This means that a good knowledge of optics is very important in order to print good photos. The
lenses in a camera are directed to bend the light so that it lands onto sensor arrays - which are grids of thousands of microscopic photocells. This grid creates picture elements (pixels) by sensing the light intensity of the image. If the sensor array has too low a resolution then the picture will look pixelated or blocky.
Friday, 16 November 2012
Week 8: Lab (manipulating images using arithmetic)
Today's lecture was on light and images. The task for the lab is to open an image in Photoshop CS4 and manipulate it using filters and arithmetic.
First I opened the file 'ch_tor.jpg' in Photoshop and rotated it so that it was the right way up. I then applied a custom filter to it.

As you can see, the custom filter made the image much sharper and very grainy.
The high pass filter made the image look quite monotone, with a glow. I thought it was quite a nice effect.

The maximum present filter mask made the image look brighter while the minimum filter made the image look darker. They both made the image look slightly blurred.
I experimented with several other filters to see the effects. Two of the filters that I tried were the Stylised: Find Edges filter and the Pixelate: Colour Halftone filter.
Find Edges:

Colour Halftone:

I then created a new filter that was all zeros except for the centre value, which I made 1. After applying this filter I did not see any difference to the image.
Next I created a filter with a two by two matrix of 1s at its centre. This filter made the image significantly whiter.

Lastly I created another filter with a two by two matrix of 1s on one diagonal and -1s on the other. This made the image almost entirely black with only a very faintly visible outline.

First I opened the file 'ch_tor.jpg' in Photoshop and rotated it so that it was the right way up. I then applied a custom filter to it.
As you can see, the custom filter made the image much sharper and very grainy.
The high pass filter made the image look quite monotone, with a glow. I thought it was quite a nice effect.

The maximum present filter mask made the image look brighter while the minimum filter made the image look darker. They both made the image look slightly blurred.
I experimented with several other filters to see the effects. Two of the filters that I tried were the Stylised: Find Edges filter and the Pixelate: Colour Halftone filter.
Find Edges:

Colour Halftone:

I then created a new filter that was all zeros except for the centre value, which I made 1. After applying this filter I did not see any difference to the image.
Next I created a filter with a two by two matrix of 1s at its centre. This filter made the image significantly whiter.
Lastly I created another filter with a two by two matrix of 1s on one diagonal and -1s on the other. This made the image almost entirely black with only a very faintly visible outline.
{kind=link}
Week 8: Lecture (Light)
Today's lecture was on light. Light is a form of energy that is detected by the human eye. It can seem to behave like a wave in some conditions and like a stream of particles in other situations. Light is not like sound - it does not need a medium to travel through. This is why light can reach us from the sun despite space being a vacuum.
Like water, light is a transverse wave. The vibrations are at right angles to the direction of motion from the source of the light.

The visible light spectrum ranges from red to violet. Just outside of this spectrum is infrared and ultraviolet. If you go lower in frequency than infrared you get microwaves and radio waves, while going higher in frequency than ultraviolet there are x-rays and gamma rays.
 'White' light is made up of the entire visible spectrum. If you shine light into a glass prism it will refract and bend to show all the different colours.
'White' light is made up of the entire visible spectrum. If you shine light into a glass prism it will refract and bend to show all the different colours.

The velocity of light depends on the medium it is travelling through. In a vacuum it travels at 3*108 m/s (or 300,000 km/s). It slows down slightly in air (but is still about 1 million times the speed of sound) and by about 2/3 in glass.
Like water, light is a transverse wave. The vibrations are at right angles to the direction of motion from the source of the light.
The visible light spectrum ranges from red to violet. Just outside of this spectrum is infrared and ultraviolet. If you go lower in frequency than infrared you get microwaves and radio waves, while going higher in frequency than ultraviolet there are x-rays and gamma rays.
The velocity of light depends on the medium it is travelling through. In a vacuum it travels at 3*108 m/s (or 300,000 km/s). It slows down slightly in air (but is still about 1 million times the speed of sound) and by about 2/3 in glass.
Friday, 9 November 2012
Week 7: Lab (audio processing)
The task for today's lab was to download a wav file called 'speechtone.wav' from the supplementary materials blog (here) and examine the file audibly, in time and frequency. Since I decided to carry out this task on my laptop at home (due to not being able to concentrate in the lab) I used Adobe Audition CS 5.5 to view and edit the file.
Here is what the sound file looked like when I first opened it:

Here is what the sound file looked like when I first opened it:

I found the file incredibly difficult to listen to or work with due to the tone in the background. To be perfectly honest it made me feel like putting my fingers in my ears! Despite my discomfort from my hypersensitive hearing I still attempted the rest of the task.
The next part of the task was to devise a strategy to improve the quality of the speech contained in the wav file. The first thing I tried was to add a special effect of 'speech enhancement'. This did not seem to improve the actual quality of the speech though.
I then tried another effect (after undoing the first) called 'speech volume leveller'. This particular effect only seemed to reduce the volume level of the entire file, not specifically the speech.
The last effect I tried was to 'normalise' the wav file. This did improve the quality of the speech, but also made the background tone even more unbearable to my ears!
I will come back to the last three parts of the task once I have worked out a strategy to make the background tone less painful to listen to.
-----------------------
I could not work with the file without hurting my ears, so after doing some research I decided to write down what I think would have worked instead.
The next part of the task was to devise a strategy to improve the quality of the speech contained in the wav file. The first thing I tried was to add a special effect of 'speech enhancement'. This did not seem to improve the actual quality of the speech though.
I then tried another effect (after undoing the first) called 'speech volume leveller'. This particular effect only seemed to reduce the volume level of the entire file, not specifically the speech.
The last effect I tried was to 'normalise' the wav file. This did improve the quality of the speech, but also made the background tone even more unbearable to my ears!
I will come back to the last three parts of the task once I have worked out a strategy to make the background tone less painful to listen to.
-----------------------
I could not work with the file without hurting my ears, so after doing some research I decided to write down what I think would have worked instead.
The speech in the file is hard to make out because there is a continuous tone in the background. This tone has a consistent sound level. Therefore to remove the high-frequency tone you could go into the Spectral Frequency Display, select the high frequency area and remove it. To improve the speech left behind you could apply a vocal enhancer effect.
To make the voice sound angry you could increase the volume and also make the start of each word louder.
Lastly, to make the file sound as if it was recorded in a church hall a convolution reverb could be added to it.
Friday, 2 November 2012
Week 6: Lab (analysing and modifying signals)
Musical and Non Musical Audio
Applying effects using Soundbooth - Compression:
First I opened Soundbooth CS4 and the 'sopranoascenddescend' WAV file. I applied a compression effect to the waveform. While this compressed the waveform and changed how it looked it didn't seem to affect how it sounded.
Compressors:
Compressors are used to limit or decrease the dynamic range between the quietest and loudest parts of an audio signal. They achieve this by boosting the quieter parts of the signal and reducing the louder parts.

The program is showing the wave's frequency over time as a spectrogram.
This is the spectral frequency display for the 'englishwords' WAV file. As you can see it is quite dramatically different. Instead of a continuous pattern there are gaps with no colour, showing the gaps between the words. Most of the speech energy appears to be in the lower frequencies - particularly up to 1KHz.
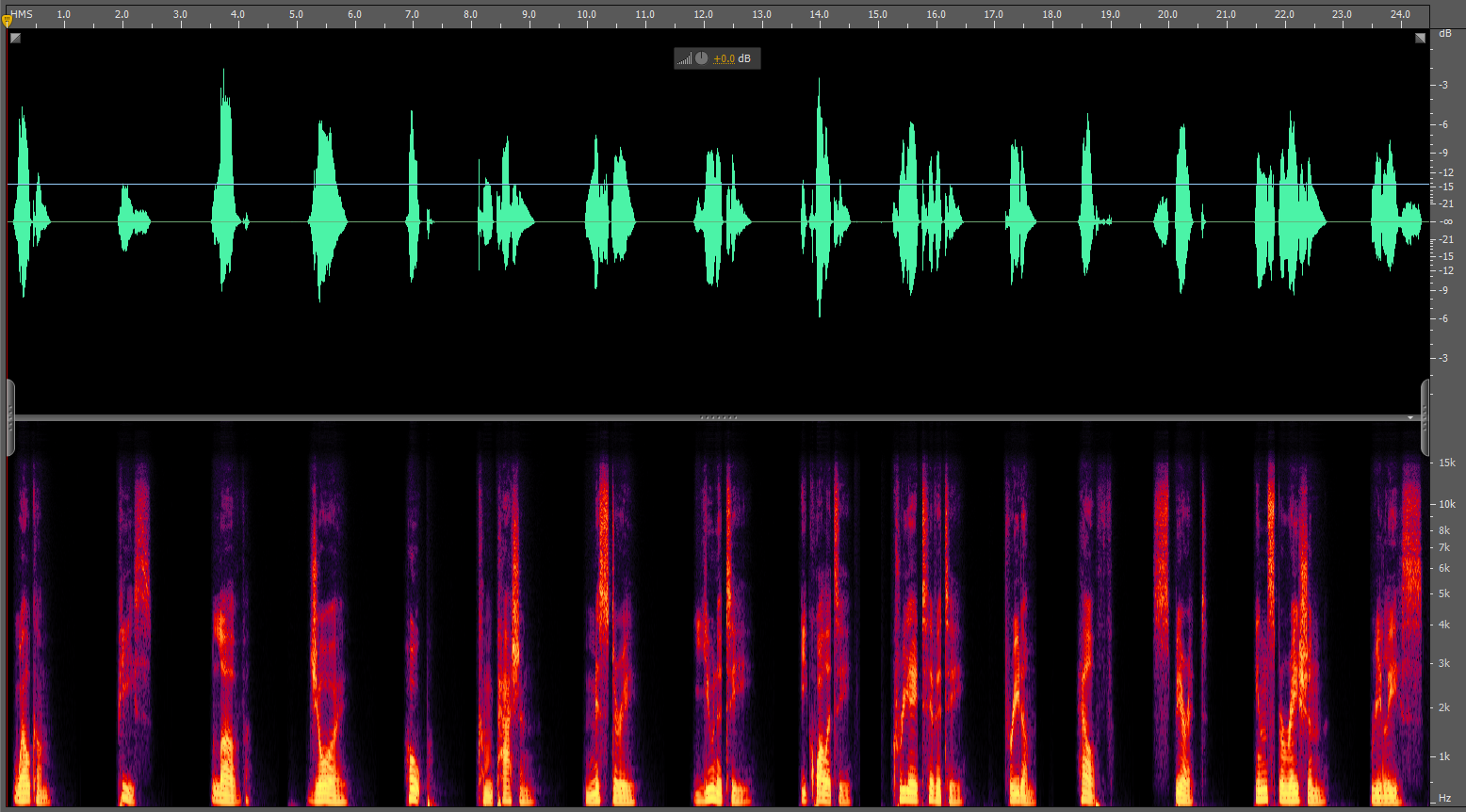
Applying effects using Soundbooth - Reverbs:
The next task was to apply a convolution reverb with a 'clean-room-aggressive' preset to the 'englishwords' WAV file. This effect made the file sound like it was recorded in a large room since there was a slight delay to the words.
Applying effects using Soundbooth - Compression:
First I opened Soundbooth CS4 and the 'sopranoascenddescend' WAV file. I applied a compression effect to the waveform. While this compressed the waveform and changed how it looked it didn't seem to affect how it sounded.
Compressors:
Compressors are used to limit or decrease the dynamic range between the quietest and loudest parts of an audio signal. They achieve this by boosting the quieter parts of the signal and reducing the louder parts.
Compression is used to make a sound more consistent and even. Instead of some parts being very quiet and some parts very loud, the overall volume is evened out.
Benefits of using a compressor are:
Benefits of using a compressor are:
- increasing the overall gain of a wave by compressing the peaks
- useful for making vocal performance stand out more from the backing instruments
- useful for making vocal performance stand out more from the backing instruments
- used in broadcasting to boost the volume of audio signals and reducing the dynamic range so that they can be broadcasted by narrow-range broadcast signals.
Looking at Spectrograms:
Then I selected the spectral frequency display view. This is what was displayed on the screen in Soundbooth:
Looking at Spectrograms:
Then I selected the spectral frequency display view. This is what was displayed on the screen in Soundbooth:
This is the spectral frequency display for the 'englishwords' WAV file. As you can see it is quite dramatically different. Instead of a continuous pattern there are gaps with no colour, showing the gaps between the words. Most of the speech energy appears to be in the lower frequencies - particularly up to 1KHz.
Applying effects using Soundbooth - Reverbs:
The next task was to apply a convolution reverb with a 'clean-room-aggressive' preset to the 'englishwords' WAV file. This effect made the file sound like it was recorded in a large room since there was a slight delay to the words.
After that, I applied the same reverb effect, but with a 'roller disco aggressive' preset instead. This made the file sound very far away from the listener.
About Reverbs:
Reverberations in a room are the reflections of sound waves hitting off various different surfaces (e.g. walls, desks, ceiling, floor) and reaching your ear. Since they take less than 0.1 secs of time difference to reach your ear from the original sound source they are processed all together and may just result in hearing the sound for a slightly prolonged time.

Speech transcript:
Next I reopened the original 'englishwords' WAV file and selected Edit/SpeechTranscript Transcribe.
The result was:
[Speaker 0] welcome the police allow for sure I hope compassion
[Speaker 1] in mystery the unity he quality creativity free and help steer it inspiration really is
Since the actual transcript is completely different it seems like the computer is attempting to make sense of the random words by trying to put the sounds into sentences.
Computer Speech Transcription:
Computer Speech Transcription works by detecting the words that are said in digital audio files and converting them into written words. This process is very complicated and in terms of performance it is based on speed and accuracy.
About Reverbs:
Reverberations in a room are the reflections of sound waves hitting off various different surfaces (e.g. walls, desks, ceiling, floor) and reaching your ear. Since they take less than 0.1 secs of time difference to reach your ear from the original sound source they are processed all together and may just result in hearing the sound for a slightly prolonged time.
Speech transcript:
Next I reopened the original 'englishwords' WAV file and selected Edit/SpeechTranscript Transcribe.
The result was:
[Speaker 0] welcome the police allow for sure I hope compassion
[Speaker 1] in mystery the unity he quality creativity free and help steer it inspiration really is
Since the actual transcript is completely different it seems like the computer is attempting to make sense of the random words by trying to put the sounds into sentences.
Computer Speech Transcription:
Computer Speech Transcription works by detecting the words that are said in digital audio files and converting them into written words. This process is very complicated and in terms of performance it is based on speed and accuracy.
Friday, 26 October 2012
Week 5: Dynamic Range
In the lab for week 5 we were asked to open the 'englishwords' WAV file in Soundbooth and work out its dynamic range. Unfortunately though Soundbooth does not use decibels as a measurement, instead using dBFS (decibels below full scale) which results in negative values. As far as I'm aware it is not possible to get a log of a negative number so I could not find out the dynamic range.
The dynamic range of an audio signal is the ratio between the largest and smallest possible values.
The dynamic range of an audio signal is the ratio between the largest and smallest possible values.
Sunday, 21 October 2012
Week 4: Lab (audio wave processing)
As I found the lab a bit too loud (with earplugs) and couldn't download the audio files we were supposed to be working on (due to Google's download limit) I decided to do the lab activity at home. The only difference being that I would use Adobe Soundbooth CS5 instead of CS4.
The first task after downloading the two music files - 'sopranoascenddescend.wav' and 'english words2.wav' was to play the soprano file in Windows Media Player and look at how long it was. Of course when using Windows 7 you could just click on the file in Explorer and get the length from there, but I played it anyway. It was 7 seconds long.
I have never used Adobe Soundbooth before so that was a new experience. I have however used Adobe Audition - which has more features but a very similar workspace. Therefore I already knew how to use all the basic tools.

I applied a Reverb effect to the file to see what it would sound like. It added an echo to the words in the file which gave the impression that it had been recorded in a very large echoey room.
I then undid that effect and added a Special: Sci-Fi Sounds effect instead. This resulted in the file sounding like the words had been spoken underwater.
Lastly I tried using a Voice: Telephone effect. This made the voice on the file sound much quieter and slightly electronic and distorted, giving the impression that the voice had been recorded from a telephone conversation.
The first task after downloading the two music files - 'sopranoascenddescend.wav' and 'english words2.wav' was to play the soprano file in Windows Media Player and look at how long it was. Of course when using Windows 7 you could just click on the file in Explorer and get the length from there, but I played it anyway. It was 7 seconds long.
I have never used Adobe Soundbooth before so that was a new experience. I have however used Adobe Audition - which has more features but a very similar workspace. Therefore I already knew how to use all the basic tools.

I applied a Reverb effect to the file to see what it would sound like. It added an echo to the words in the file which gave the impression that it had been recorded in a very large echoey room.
I then undid that effect and added a Special: Sci-Fi Sounds effect instead. This resulted in the file sounding like the words had been spoken underwater.
Lastly I tried using a Voice: Telephone effect. This made the voice on the file sound much quieter and slightly electronic and distorted, giving the impression that the voice had been recorded from a telephone conversation.
Saturday, 20 October 2012
Week 4: Hearing
How human hearing works
The human ear is responsible for converting variations in
air pressure – from speech, music, or other sources – into the neural activity that
our brains can perceive and interpret. The ear can be divided into three
sections: the outer ear, the middle ear and the inner ear. Each of these parts
performs a specific function in processing sound information.

Sound waves are first collected by the outer ear, which is
made up of the external ear (also called the pinna) and a canal that leads to
the eardrum. The external ear amplifies sound, particularly at the frequency
ranges of 2,000 to 5,000 Hz – a range that is important for speech perception.
The shape of the external ear is also important for sound localisation –
picking up where the sound is coming from.

From the ear canal, the sound waves vibrate the eardrum,
which in turn vibrates three tiny bones in the middle ear. These three tiny
bones are called the malleus, incus and stapes. The stapes vibrates a small
membrane at the base of the cochlea (which is called the oval window) which
transmits amplified vibrational energy to cochlea, which is full of fluid. The
round window separates the tympanic canal from the middle ear.

The inner ear converts sound into neural activity. The
auditory portion of the inner ear is a coiled structure called the cochlea. The
region nearest the oval-window membrane is the base of the spiral; the other
end, or top, is referred to as the apex.

Inside the length of the cochlea are three parallel canals;
the tympanic canal, the vestibular canal, and the middle canal. The main
elements for converting sounds into neural activity are found on the basilar
membrane, a flexible structure that separates the tympanic canal from the
middle canal.

This diagram shows the cochlea ‘unrolled’ so that we can see
the basilar membrane more clearly.

The basilar membrane is about five times wider at the apex (top)
of the cochlea than at the base, even though the cochlea itself gets narrower towards
its apex. It vibrates in response to sound transmitted to the cochlea from the
middle ear.
High frequency sounds displace the narrow, stiff base of the
basilar membrane more than they displace the wider, more flexible apex.
Mid-frequency sounds maximally displace the middle of the basilar membrane.
Lower frequency sounds maximally displace the apex.
Within the middle canal and on top of the basilar membrane
is the organ of Corti. The organ of Corti is the collective term for all the
elements involved in the transduction of sounds. It includes three main
structures: the sensory cells (hair cells), a complicated framework of
supporting cells, and the end of the auditory nerve fibres.


On the top of the organ of Corti is the tectorial membrane.
The stereocilia of the outer hair cells extend into indentations in the bottom
of the tectorial membrane.

The movement of fluid in the cochlea produces vibrations of
the basilar membrane. These vibrations bend the stereocilia inserted into the
tectorial membrane. Depending on the direction of the bend, the hair cells will
either increase or decrease the firing rate of auditory nerve fibres.

References:
The human ear - http://bcs.whfreeman.com/thelifewire/content/chp45/4502001.html
Sunday, 14 October 2012
Week 3: Digital Signal Processing
This week we covered quite a lot of topics. Ironically I couldn't listen to most of the lecture due to having my fingers in my ears to block out the painful sound effects included with the slides. Turns out learning about audio processing is tricky when you have hypersensitive hearing.
Missing most of the lecture made the class test afterwards quite difficult. I could not process what we were meant to be doing in the lab either due to the lack of written instructions and too much background noise so I have just read through the lecture notes, picked out the topics I hadn't yet covered in my blog and researched them.
Harmonics
Harmonics are the specific frequencies created by standing waves. The 'fundamental' of the harmonic is the loudest tone you can hear. A harmonic is a integer multiple of the fundamental's frequency (e.g. if the fundamental is 'f' you can get 2f, 3f, 4f, etc.).

Sound intensity and level
Sound intensity measurements are extremely difficult to make so the intensity of sound is generally expressed as an equivalent sound level. This is done by comparing any sound to a standard sound intensity (the quietest 1KHz tone the average human can hear).
Echoes and Reverberation
Reverberations are the reflections of sound waves hitting off various different surfaces (e.g. walls, desks, ceiling, floor) and reaching your ear. Since they take less than 0.1 secs of time difference to reach your ear from the original sound source they are processed all together and may just result in hearing the sound for a slightly prolonged time.
Echoes on the other hand are reflections of sound that have a time delay of more than 0.1 secs. Because of this delay there is a gap between the original sound and the reflection. The second sound hear is called an echo.
The Inverse-Square Law
The Inverse-Square Law means that the intensity of the sound heard varies inversely as the square of the distance 'R' from the source of the sound.
Sound will be roughly nine times less intense at a distance of 3m from its origin, as at a distance of 1m in open air.
Spectrum
A spectrum is a graph of sound level (amplitude) against frequency over a short period of time. Since many sound waves contain different frequencies this graph is often useful.

Spectrogram
Instead of a spectrum, the variation of sound intensity with time and frequency can be displayed by representing intensity by colour or brightness on a frequency vs time axis. This is called a spectrogram.

Digital Signal Processing Systems

Why use digital processing?
1. Precision
Precision of DSP systems is only limited by the conversion process at both input and output - analogue to digital and vice versa. This is only in theory though since in reality the sampling rate and word length (no. of bits) restrictions affect the precision.
2. Robustness
Digital systems are less susceptible to component tolerance and electrical noise (pick-up) variations due to logic noise margins.
An important factor for complex systems is that adjustments for electrical drift and component ageing are essentially removed.
3. Flexibility
Flexibility of the DSP is due to its programmability, which allows it to be upgraded and for its processing operations to be expanded easily without necessarily incurring large scale hardware changes.
Sound card architecture

Sampling a signal
Sampling a signal is when the system samples the signal at a specific time, nT seconds. It the continues sampling the signal over periods of T seconds.

References:
Echos and reverberation: http://www.physicsclassroom.com/mmedia/waves/er.cfm
Spectrum graphic: http://www.tablix.org/~avian/blog/archives/2008/11/the_sound_of_hot_tea/
Sampling: http://cnx.org/content/m15655/latest/
Missing most of the lecture made the class test afterwards quite difficult. I could not process what we were meant to be doing in the lab either due to the lack of written instructions and too much background noise so I have just read through the lecture notes, picked out the topics I hadn't yet covered in my blog and researched them.
Harmonics
Harmonics are the specific frequencies created by standing waves. The 'fundamental' of the harmonic is the loudest tone you can hear. A harmonic is a integer multiple of the fundamental's frequency (e.g. if the fundamental is 'f' you can get 2f, 3f, 4f, etc.).

Sound intensity and level
Sound intensity measurements are extremely difficult to make so the intensity of sound is generally expressed as an equivalent sound level. This is done by comparing any sound to a standard sound intensity (the quietest 1KHz tone the average human can hear).
Echoes and Reverberation
Reverberations are the reflections of sound waves hitting off various different surfaces (e.g. walls, desks, ceiling, floor) and reaching your ear. Since they take less than 0.1 secs of time difference to reach your ear from the original sound source they are processed all together and may just result in hearing the sound for a slightly prolonged time.
Echoes on the other hand are reflections of sound that have a time delay of more than 0.1 secs. Because of this delay there is a gap between the original sound and the reflection. The second sound hear is called an echo.
The Inverse-Square Law
The Inverse-Square Law means that the intensity of the sound heard varies inversely as the square of the distance 'R' from the source of the sound.
Sound will be roughly nine times less intense at a distance of 3m from its origin, as at a distance of 1m in open air.
Spectrum
A spectrum is a graph of sound level (amplitude) against frequency over a short period of time. Since many sound waves contain different frequencies this graph is often useful.

Spectrogram
Instead of a spectrum, the variation of sound intensity with time and frequency can be displayed by representing intensity by colour or brightness on a frequency vs time axis. This is called a spectrogram.

Digital Signal Processing Systems

Steps in a Digital Signal Processing System:
1. The signal is inputted via a microphone or other recording equipment.
2. The recording is then converted from analogue to digital (into binary numbers).
3. Editing is then done to the digital copy (e.g filtering, pitch warp, echo, reverb, etc.).
4. The signal is then changed from digital back into analogue.
5. Then the signal is smoothed out.
6. The edited recording is outputted.
Computers cannot understand analogue signals, which is why they must be converted into digital first and then converted back again so that we can listen and process them.
Why use digital processing?
1. Precision
Precision of DSP systems is only limited by the conversion process at both input and output - analogue to digital and vice versa. This is only in theory though since in reality the sampling rate and word length (no. of bits) restrictions affect the precision.
2. Robustness
Digital systems are less susceptible to component tolerance and electrical noise (pick-up) variations due to logic noise margins.
An important factor for complex systems is that adjustments for electrical drift and component ageing are essentially removed.
3. Flexibility
Flexibility of the DSP is due to its programmability, which allows it to be upgraded and for its processing operations to be expanded easily without necessarily incurring large scale hardware changes.
Sound card architecture

Sampling a signal
Sampling a signal is when the system samples the signal at a specific time, nT seconds. It the continues sampling the signal over periods of T seconds.

The rate that a signal is usually sampled at is double the frequency of the human hearing range. For example, a signal heard at 10 Hz would be sampled at 20Hz.
References:
Echos and reverberation: http://www.physicsclassroom.com/mmedia/waves/er.cfm
Spectrum graphic: http://www.tablix.org/~avian/blog/archives/2008/11/the_sound_of_hot_tea/
Sampling: http://cnx.org/content/m15655/latest/
Subscribe to:
Comments (Atom)